Publications
2025
-
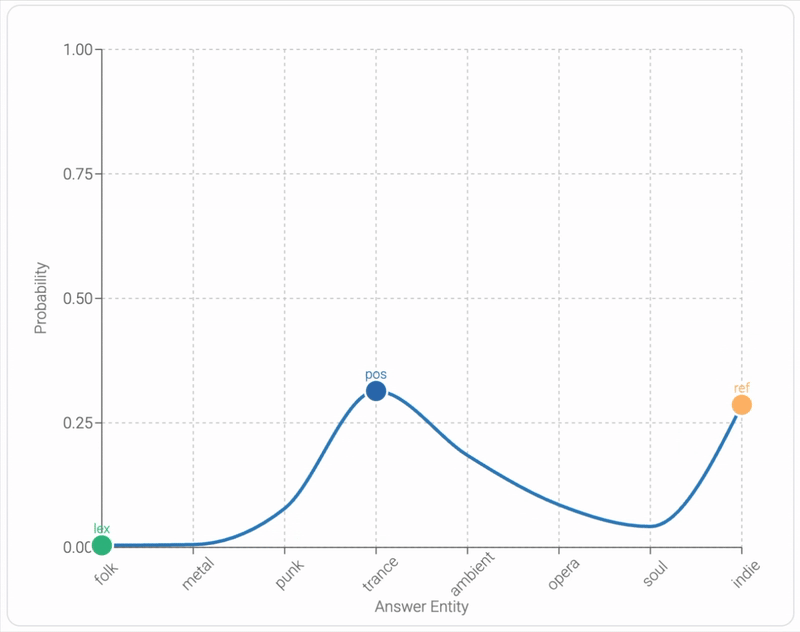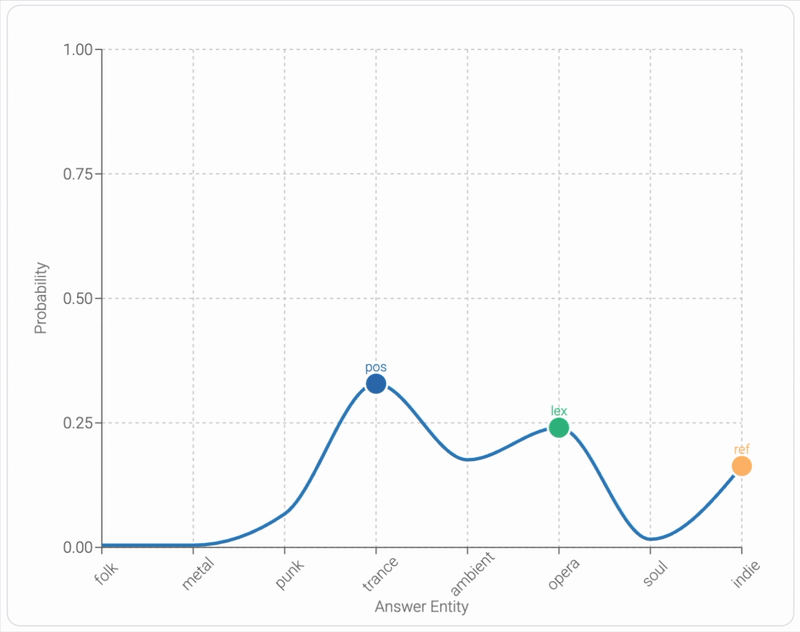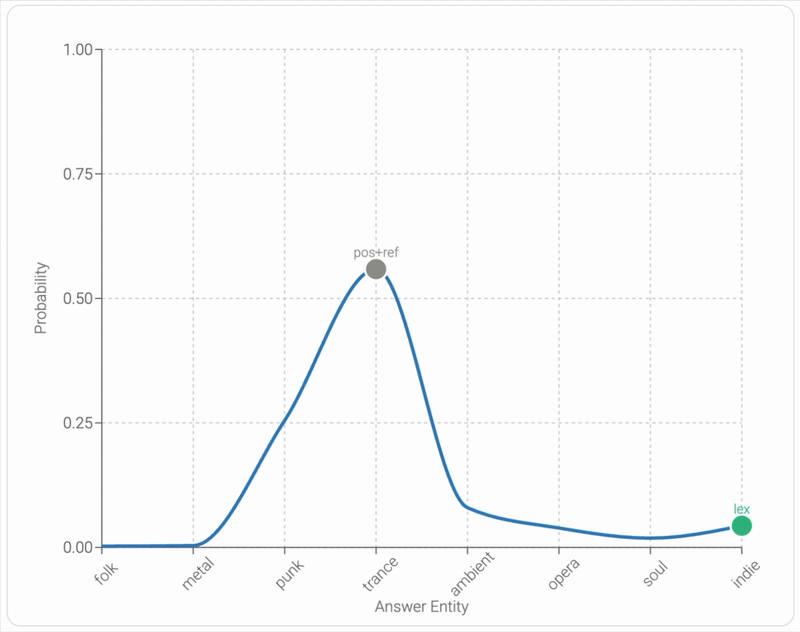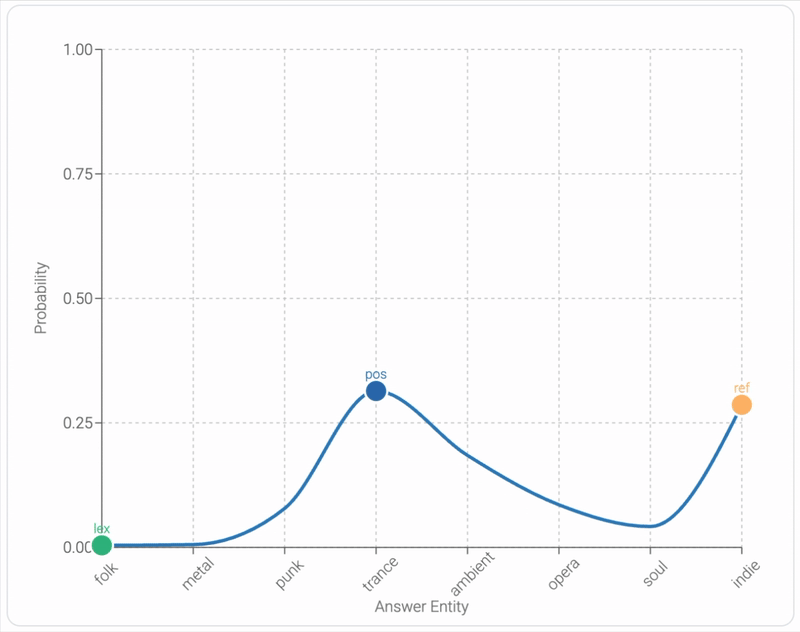 Mixing Mechanisms: How Language Models Retrieve Bound Entities In-ContextYoav Gur-Arieh, Mor Geva, and Atticus Geiger2025
Mixing Mechanisms: How Language Models Retrieve Bound Entities In-ContextYoav Gur-Arieh, Mor Geva, and Atticus Geiger2025A key component of in-context reasoning is the ability of language models (LMs) to bind entities for later retrieval. For example, an LM might represent "Ann loves pie" by binding "Ann" to "pie", allowing it to later retrieve "Ann" when asked "Who loves pie?" Prior research on short lists of bound entities found strong evidence that LMs implement such retrieval via a positional mechanism, where "Ann" is retrieved based on its position in context. In this work, we find that this mechanism generalizes poorly to more complex settings; as the number of bound entities in context increases, the positional mechanism becomes noisy and unreliable in middle positions. To compensate for this, we find that LMs supplement the positional mechanism with a lexical mechanism (retrieving "Ann" using its bound counterpart "pie") and a reflexive mechanism (retrieving "Ann" through a direct pointer). Through extensive experiments on nine models and ten binding tasks, we uncover a consistent pattern in how LMs mix these mechanisms to drive model behavior. We leverage these insights to develop a causal model combining all three mechanisms that estimates next token distributions with 95% agreement. Finally, we show that our model generalizes to substantially longer inputs of open-ended text interleaved with entity groups, further demonstrating the robustness of our findings in more natural settings. Overall, our study establishes a more complete picture of how LMs bind and retrieve entities in-context.
@misc{gurarieh2025mixingmechanismslanguagemodels, title = {Mixing Mechanisms: How Language Models Retrieve Bound Entities In-Context}, author = {Gur-Arieh, Yoav and Geva, Mor and Geiger, Atticus}, year = {2025}, eprint = {2510.06182}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2510.06182}, } -
 LMEnt: A Suite for Analyzing Knowledge in Language Models from Pretraining Data to RepresentationsDaniela Gottesman, Alon Gilae-Dotan, Ido Cohen, Yoav Gur-Arieh, Marius Mosbach, Ori Yoran, and 1 more author2025
LMEnt: A Suite for Analyzing Knowledge in Language Models from Pretraining Data to RepresentationsDaniela Gottesman, Alon Gilae-Dotan, Ido Cohen, Yoav Gur-Arieh, Marius Mosbach, Ori Yoran, and 1 more author2025@misc{gottesman2025lmentsuiteanalyzingknowledge, title = {LMEnt: A Suite for Analyzing Knowledge in Language Models from Pretraining Data to Representations}, author = {Gottesman, Daniela and Gilae-Dotan, Alon and Cohen, Ido and Gur-Arieh, Yoav and Mosbach, Marius and Yoran, Ori and Geva, Mor}, year = {2025}, eprint = {2509.03405}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2509.03405}, } - EMNLP
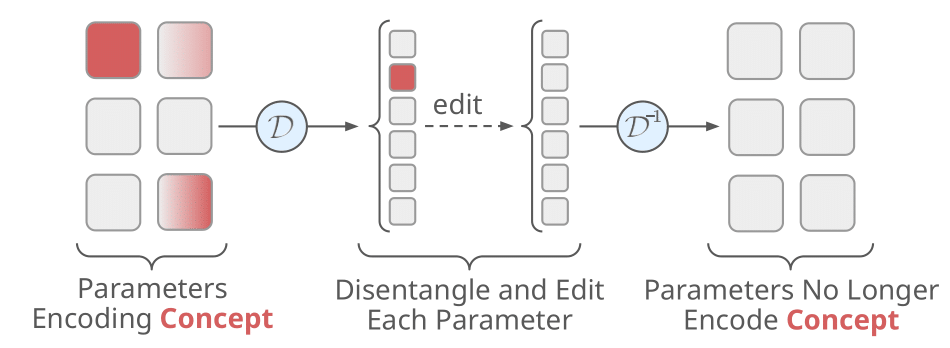 Precise In-Parameter Concept Erasure in Large Language ModelsYoav Gur-Arieh, Clara Suslik, Yihuai Hong, Fazl Barez, and Mor Geva2025
Precise In-Parameter Concept Erasure in Large Language ModelsYoav Gur-Arieh, Clara Suslik, Yihuai Hong, Fazl Barez, and Mor Geva2025Large language models (LLMs) often acquire knowledge during pretraining that is undesirable in downstream deployments, e.g., sensitive information or copyrighted content. Existing approaches for removing such knowledge rely on fine-tuning, training low-rank adapters or fact-level editing, but these are either too coarse, too shallow, or ineffective. In this work, we propose PISCES (Precise In-parameter Suppression for Concept EraSure), a novel framework for precisely erasing entire concepts from model parameters by directly editing directions that encode them in parameter space. PISCES uses a disentangler model to decompose MLP vectors into interpretable features, identifies those associated with a target concept using automated interpretability techniques, and removes them from model parameters. Experiments on Gemma 2 and Llama 3.1 over various concepts show that PISCES achieves modest gains in efficacy over leading erasure methods, reducing accuracy on the target concept to as low as 7.7%, while dramatically improving erasure specificity (by up to 31%) and robustness (by up to 38%). Overall, these results demonstrate that feature-based in-parameter editing enables a more precise and reliable approach for removing conceptual knowledge in language models.
@misc{gurarieh2025preciseinparameterconcepterasure, title = {Precise In-Parameter Concept Erasure in Large Language Models}, author = {Gur-Arieh, Yoav and Suslik, Clara and Hong, Yihuai and Barez, Fazl and Geva, Mor}, year = {2025}, booktitle = {The 2025 Conference on Empirical Methods in Natural Language Processing}, eprint = {2505.22586}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2505.22586}, } - ACL
 Enhancing Automated Interpretability with Output-Centric Feature DescriptionsYoav Gur-Arieh, Roy Mayan, Chen Agassy, Atticus Geiger, and Mor GevaIn The 63rd Annual Meeting of the Association for Computational Linguistics, 2025
Enhancing Automated Interpretability with Output-Centric Feature DescriptionsYoav Gur-Arieh, Roy Mayan, Chen Agassy, Atticus Geiger, and Mor GevaIn The 63rd Annual Meeting of the Association for Computational Linguistics, 2025Automated interpretability pipelines generate natural language descriptions for the concepts represented by features in large language models (LLMs), such as plants or the first word in a sentence. These descriptions are derived using inputs that activate the feature, which may be a dimension or a direction in the model’s representation space. However, identifying activating inputs is costly, and the mechanistic role of a feature in model behavior is determined both by how inputs cause a feature to activate and by how feature activation affects outputs. Using steering evaluations, we reveal that current pipelines provide descriptions that fail to capture the causal effect of the feature on outputs. To fix this, we propose efficient, output-centric methods for automatically generating feature descriptions. These methods use the tokens weighted higher after feature stimulation or the highest weight tokens after applying the vocabulary "unembedding" head directly to the feature. Our output-centric descriptions better capture the causal effect of a feature on model outputs than input-centric descriptions, but combining the two leads to the best performance on both input and output evaluations. Lastly, we show that output-centric descriptions can be used to find inputs that activate features previously thought to be "dead".
@inproceedings{gurarieh2025enhancing, title = {Enhancing Automated Interpretability with Output-Centric Feature Descriptions}, author = {Gur-Arieh, Yoav and Mayan, Roy and Agassy, Chen and Geiger, Atticus and Geva, Mor}, year = {2025}, booktitle = {The 63rd Annual Meeting of the Association for Computational Linguistics}, url = {https://arxiv.org/abs/2501.08319}, }



